![[Cloud OnAir] AutoML Vision で学ぶ「実践的」機械学習 [2018年11月29日放送]](https://i.ytimg.com/vi/LjqGRBfeDH4/hqdefault.jpg)
コンテンツ
- データセットの準備
- Google Cloud Platformの無料トライアルを請求する
- 新しいGCPプロジェクトを作成する
- Cloud AutoMLおよびストレージAPIを有効にします
- Cloud Storageバケットを作成する
- トレーニングの時間:データセットの構築
- 機械学習モデルのトレーニング
- モデルはどれくらい正確ですか?
- モデルをテストしてください!
- まとめ
機械学習(ML)は、コンピューターが自分自身を教えるというサイエンスフィクションの概念です。 MLでは、機械学習モデルに自動的に処理させたいコンテンツのタイプを表すデータを提供し、モデルはそのデータに基づいて自分自身を学習します。
機械学習は最先端かもしれませんが、同時に 巨大 参入障壁。あらゆる種類のMLを使用する場合は、通常、機械学習の専門家またはデータサイエンティストを雇う必要があり、これらの職業は現在非常に高い需要があります。
GoogleのCloud AutoML Visionは、MLの経験がなくても機械学習モデルを作成できるようにすることで、MLを大衆にもたらすことを目的とした新しい機械学習サービスです。 Cloud AutoML Visionを使用すると、写真のコンテンツとパターンを識別できる画像認識モデルを作成し、このモデルを使用して後続の画像を自動的に処理できます。
この種の視覚ベースのMLは、さまざまな方法で使用できます。ユーザーがスマートフォンを向けているランドマーク、製品、またはバーコードに関する情報を提供するアプリを作成したいですか?または、ユーザーが素材、色、スタイルなどの要因に基づいて何千もの製品をフィルターできる強力な検索システムを作成したいですか?機械学習は、この種の機能を提供する最も効果的な方法の1つです。
まだベータ版ですが、Cloud AutoML Visionを使用して、写真のパターンとコンテンツを識別するカスタムの機械学習モデルを構築できます。機械学習のすべての話題について知りたい場合は、この記事で独自の画像認識モデルを作成し、それを使用して新しい写真を自動的に処理する方法を紹介します。
データセットの準備

Cloud AutoMLを使用する場合、ラベル付きの写真をデータセットとして使用します。好きな写真やラベルを使用できますが、このチュートリアルをわかりやすくするために、犬の写真と猫の写真を区別できる簡単なモデルを作成します。
モデルの仕様が何であれ、最初のステップは適切な写真を調達することです!
Cloud AutoML Visionには、ラベルごとに少なくとも10個の画像、または高度なモデル(画像ごとに複数のラベルになるモデルなど)には50個以上の画像が必要です。ただし、提供するデータが多いほど、モデルが後続のコンテンツを正しく識別する可能性が高くなるため、AutoML Visionのドキュメントでは、 少なくとも モデルごとに100個の例。また、ラベルごとにほぼ同じ数のサンプルを提供する必要があります。不公平な分布は、モデルが最も「人気のある」カテゴリへの偏りを示すのを助長するためです。
最良の結果を得るには、トレーニング画像はこのモデルが遭遇するさまざまな画像を表す必要があります。たとえば、異なる角度、より高い解像度とより低い解像度、異なる背景で撮影した画像を含める必要があります。 AutoML Visionは、JPEG、PNG、WEBP、GIF、BMP、TIFF、およびICOの形式の画像を受け入れ、最大ファイルサイズは30MBです。
Cloud AutoML Visionサービスを実験しているだけなので、できるだけ早く簡単にデータセットを作成することをお勧めします。物事を簡単にするために、Pexelsから犬と猫の無料のストック写真をダウンロードし、それらの写真を後で簡単にアップロードできるように、猫と犬の写真を別々のフォルダーに保存します。
実稼働環境で使用するデータセットを構築する場合は、責任あるAIプラクティスを考慮に入れて、不利な取り扱いを防ぐ必要があることに注意してください。このトピックの詳細については、GoogleのInclusive ML GuideとResponsible AI Practicesのドキュメントをご覧ください。
AutoMl Visionにデータをアップロードするには、次の3つの方法があります。
- ラベルに対応するフォルダーに既にソートされている画像をアップロードします。
- 画像とそれに関連するカテゴリラベルを含むCSVファイルをインポートします。これらの写真は、ローカルコンピューターまたはGoogle Cloud Storageからアップロードできます。
- Google Cloud AutoML Vision UIを使用して画像をアップロードし、各画像にラベルを適用します。これが、このチュートリアルで使用する方法です。
Google Cloud Platformの無料トライアルを請求する
Cloud AutoML Visionを使用するには、Google Cloud Platform(GCP)アカウントが必要です。アカウントをお持ちでない場合は、Try Cloud Platform for freeページに移動し、指示に従うことで12か月の無料トライアルにサインアップできます。君は 意志 デビットカードまたはクレジットカードの詳細を入力する必要がありますが、無料利用枠のよくある質問によると、これらは本人確認にのみ使用され、有料アカウントにアップグレードしない限り請求されません。
もう1つの要件は、AutoMLプロジェクトの課金を有効にする必要があることです。無料トライアルにサインアップしたばかりの場合、またはGPCアカウントに関連付けられた支払い情報がない場合は、次のようにします。
- GCP Consoleに移動します。
- ナビゲーションメニュー(画面の左上隅にある並んだアイコン)を開きます。
- [請求]を選択します。
- [課金]ドロップダウンメニューを開き、[課金アカウントの管理]を選択します。
- [アカウントを作成]を選択し、画面の指示に従って請求プロファイルを作成します。
新しいGCPプロジェクトを作成する
これで、最初のCloud AutoML Visionプロジェクトを作成する準備ができました。
- [リソースの管理]ページに移動します。
- 「プロジェクトを作成」をクリックします。
- プロジェクトに名前を付けて、「作成」をクリックします。
複数の請求先アカウントがある場合、GCPはこのプロジェクトに関連付けるアカウントを尋ねる必要があります。単一の請求先アカウントがある場合 そして あなたが課金管理者である場合、このアカウントはプロジェクトに自動的にリンクされます。
または、請求先アカウントを手動で選択できます。
- GCP Consoleのナビゲーションメニューを開き、[課金]を選択します。
- [請求先アカウントをリンク]を選択します。
- [アカウントの設定]を選択し、このプロジェクトに関連付ける請求先アカウントを選択します。
Cloud AutoMLおよびストレージAPIを有効にします
モデルを作成するときに、すべてのトレーニング画像をCloud Storageバケットに保存するため、AutoMLを有効にする必要があります そして Google Cloud Storage API:
- GCPナビゲーションメニューを開き、[APIとサービス]> [ダッシュボード]を選択します。
- [APIとサービスを有効にする]をクリックします。
- 「Cloud AutoML API」と入力し始め、表示されたら選択します。
- 「有効にする」を選択します。
- [APIとサービス]> [ダッシュボード]> [APIとサービスを有効にする]画面に戻ります。
- 「Google Cloud Storage」と入力し始め、表示されたら選択します。
- 「有効にする」を選択します。
Cloud Storageバケットを作成する
オンラインのLinuxベースの仮想マシンであるCloud Shellを使用して、Cloud Storageバケットを作成します。
- ヘッダーバーから「Google Cloud Shellをアクティブにする」アイコンを選択します(次のスクリーンショットのカーソルがあります)。
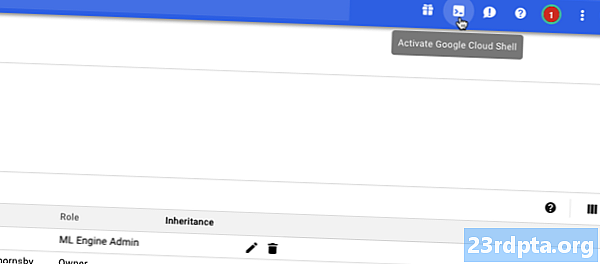
- これで、コンソールの下部に沿ってCloud Shellセッションが開きます。 Google Cloud Shellがプロジェクトに接続するまで待ちます。
- 次のコマンドをコピーしてGoogle Cloud Shellに貼り付けます。
PROJECT = $(gcloud config get-value project)&& BUCKET = "$ {PROJECT} -vcm"
- キーボードの「Enter」キーを押します。
- 次のコマンドをコピーしてGoogle Cloud Shellに貼り付けます。
gsutil mb -p $ {PROJECT} -c Regional -l us-central1 gs:// $ {BUCKET}
- 「Enter」キーを押します。
- 次のコマンドをコピーして貼り付け、「Enter」キーを押して、AutoMLサービスにGoogle Cloudリソースにアクセスする権限を付与します。
PROJECT = $(gcloud config get-value project)gcloud projects add-iam-policy-binding $ PROJECT --member = "serviceAccount:[email protected]" --role = "roles / ml。 admin "gcloudプロジェクトadd-iam-policy-binding $ PROJECT --member =" serviceAccount:[email protected] " --role =" roles / storage.admin "
トレーニングの時間:データセットの構築
この設定が完了したら、データセットをアップロードする準備ができました!これには以下が含まれます:
- 空のデータセットを作成します。
- 写真をデータセットにインポートします。
- 各写真に少なくとも1つのラベルを割り当てます。 AutoML Visionは、ラベルのない写真を完全に無視します。
ラベル付けプロセスを簡単にするために、猫の写真に取り組む前に、すべての犬の写真をアップロードしてラベルを付けます。
- AutoML Vision UIをご覧ください(執筆時点ではまだベータ版です)。
- [新しいデータセット]を選択します。
- データセットにわかりやすい名前を付けます。
- [ファイルを選択]をクリックします。
- 次のウィンドウで、すべての犬の写真を選択し、「開く」をクリックします。
- 画像には複数のラベルがないため、「マルチラベル分類を有効にする」を選択しないでおくことができます。 [データセットの作成]をクリックします。
アップロードが完了すると、Cloud AutoML Vision UIにより、すべての画像と、このデータセットに適用したラベルの内訳を含む画面が表示されます。
現在、データセットには犬の写真のみが含まれているため、それらに一括してラベルを付けることができます。
- 左側のメニューで[ラベルを追加]を選択します。
- 「dog」と入力し、キーボードの「Enter」キーを押します。
- [すべての画像を選択]をクリックします。
- 「ラベル」ドロップダウンを開き、「犬」を選択します。

これで、すべての犬の写真にラベルを付けました。次は猫の写真に移りましょう。
- ヘッダーバーから「画像を追加」を選択します。
- 「コンピューターからアップロード」を選択します。
- すべての猫の写真を選択し、「開く」をクリックします。
- 左側のメニューで[ラベルを追加]を選択します。
- 「cat」と入力し、キーボードの「Enter」キーを押します。
- 画像にカーソルを合わせて、表示された小さなチェックマークアイコンをクリックして、各猫の写真を選択します。
- [ラベル]プルダウンを開き、[猫]を選択します。
機械学習モデルのトレーニング
データセットができたので、モデルをトレーニングします。受け取ります 計算する 毎月最大10モデルのモデルごとの無料トレーニングの時間。これは内部計算の使用量を表すため、クロックの実際の時間とは相関しない場合があります。
モデルをトレーニングするには、単純に:
- AutoML Vision UIの「Train」タブを選択します。
- [トレーニングを開始]をクリックします。
Cloud AutoML Visionがモデルをトレーニングするのにかかる時間は、提供したデータの量によって異なりますが、公式ドキュメントによると約10分かかります。モデルのトレーニングが完了すると、Cloud AutoML Visionがモデルを自動的に展開し、モデルを使用する準備ができたことを通知するメールを送信します。
モデルはどれくらい正確ですか?
モデルをテストする前に、いくつかの調整を行って、予測が可能な限り正確であることを確認してください。
[評価]タブを選択し、左側のメニューからフィルターの1つを選択します。

この時点で、AutoML Vision UIはこのラベルについて次の情報を表示します。
- スコアのしきい値。 これは、新しい写真にラベルを割り当てるためにモデルが持つ必要がある信頼度です。このスライダーを使用して、付随する精度-リコールグラフの結果を監視することにより、さまざまなしきい値がデータセットに与える影響をテストできます。しきい値を低くすると、モデルがより多くの画像を分類しますが、写真を誤認するリスクが高くなります。しきい値が高い場合、モデルはより少ない画像を分類しますが、より少ない画像を誤認する必要があります。
- 平均精度。 これは、1.0が最大スコアであるため、すべてのスコアしきい値でモデルがどれだけうまく機能するかです。
- 精度。 精度が高いほど、検出される誤検知が少なくなります。これは、モデルが間違ったラベルを画像に適用する場所です。高精度モデルでは、最も関連性の高い例のみにラベルが付けられます。
- 想起。 ラベルが割り当てられるべきであったすべての例のうち、実際にラベルが割り当てられた例の数を思い出してください。再現率が高いほど、遭遇するはずの偽陰性が少なくなります。これは、モデルが画像にラベルを付けるのに失敗する場所です。
モデルをテストしてください!
ここからが面白い部分です。これまで見たことのないデータに基づいて予測を生成することにより、写真に犬または猫が含まれているかどうかをモデルが識別できるかどうかを確認します。
- その写真をつかむ じゃなかった 元のデータセットに含まれています。
- AutoML Visionコンソールで、「予測」タブを選択します。
- 「画像をアップロード」を選択します。
- AutoML Visionで分析する画像を選択します。
- しばらくすると、モデルが予測を行います-うまくいけば、それは正しいです!

Cloud AutoMLビジョンはベータ版ですが、モデルでウォームアップの遅延が発生する可能性があることに注意してください。リクエストでエラーが返された場合は、数秒待ってから再試行してください。
まとめ
この記事では、Cloud AutoML Visionを使用してカスタム学習モデルをトレーニングおよびデプロイする方法について説明しました。 AutoMLなどのツールは、機械学習を使用する人を増やす可能性があると思いますか?以下のコメントでお知らせください!


